I just realized that building the test case for the "chain delete" code would involve something that would look very similar to the "move & merge chains" code that I still have to write, so I decided to go ahead and write that instead. This is one of those cases where the test case involves code of the same nature, complexity and size as the code required to operate it. To put it another way: The "move & merge chains" code will be the test case for the "delete chains" code.
I started with "delete chains" because it gave insight into which data structures were required to provide for efficient delta-updates, without the need to actually maintain those data structures yet. As the "delete chains" code evolved, so did the representation of those data structures.
Before making "move & merge chains", a decision has to be made on how to represent chains. I decided to maintain "empty" chains as well, and that requires code to efficiently determine whether a move splits an empty chain, and if so, to actually split it. There are a plethora of ways to do it. I read the available literature and decided upon one of the proposed implementations. The goal is speed. Everything else is secondary. I will have a special case for ladders but the rest of all tactical analysis will forever build upon the code I'm writing now.
Sunday, May 14, 2006
Saturday, May 13, 2006
Inline Assembly Still Useful?
Since AGA published a devastating bogus "review" full of lies about MoyoGo (like: "It does not have a Help file"), my sales dropped to almost zero. The consequence is that I am not able to move to Czechia as I planned, to be a full-time Go programmer. So indeed , a litte collusion amongst friends does work to deny the competition a livelihood and suppress innovative Go software. The AGA eJournal has 9,000 readers and when you combine the negative "reviews" there with the boycot on ads on Sensei's Library and links from sites like GoBase, it becomes very hard to be a viable Go software developer.
Since this blog therefore isn't doing much good to persuade potential customers, I'll be heavier on the Programming side of things, so that at least fellow Go programmers might be able to benefit from it.
Which brings us to the topic: Inline Assembly language in our (C, C++ or Pascal, etc.) code. The knee-jerk response to this question is: "Due to the fact that optimization issues on modern CPU's are so complex, modern compilers generate code that is almost always better optimized than a human can do".
Which is 100% correct, but totally irrelevant to the issue!
Because we are not interested in optimized C++ code, we are interested in optimized "optimal" code! Let me explain. C++ and Pascal have "stuff they can do", like adding variables. This translates perfectly to machine opcodes, so a compiler can optimize it well.
But the processor in your computer is able to do a few things that C++ does not provide an interface to. Not all mnemonics have their equivalent higher-level language representation. What if it is possible to design the speed-sensitive part of a TsumeGo move maker/unmaker in such a way that it takes advantage of such instructions? (Hint: It is possible).
Then you're screwed, with C++ or Pascal or Java or whatever you use. Your compiler simply isn't going to compile it to efficient machine instructions, and it never will.
Compilers emit chunks of pre-defined code, mapping a higher level construct to lower-level instructions and then they optimize that output. But that's all they do. They are not creative with exotic opcodes. Yes they can do AND and OR and EXOR, but there are quite a few more interesting instructions that aren't mapped to C++ operands.
This is why, when you are serious about making a tactics module for Go (I mean serious in a quest for total world domination), you don't have much of a chance when you stick to Java or perhaps even the latest C++ compilers because I want to point out that no mainstream C++ compiler that targets 64-bit platforms is able, any more, to do inline assembly! Both Microsoft and Intel removed this feature. And it's a major hassle to maintain separate MASM assembly.
Free Pascal does allow 64-bit inline assembly. I develop MoyoGo's TsumeGo/Tactics module in 64-bit Pascal with inline assembly language. The most successful TsumeGo program, GoTools, is written in Pascal as well.
When you're a twentysomething, you probably know next to nothing about optimization techniques. Comp. Sci. does not have it in the curriculum. Unlike myself, you haven't had to tweak code running on a 1 MHz 8-bit processor. And large multinationals want to own the runtime environment, and because universities are closely affiliated to the corporate world, they have started to focus on "slow" languages like Java and C# .net.
Yes, I know there are compilers for those languages, but the resulting code is not fast, for various reasons, one of which is the concept of a garbage collector. But a language designed with the utmost contempt for speed, designed to be exclusively used where speed is of no concern, never is going to get highly optimizing compilers. Writing a good optimizer is rocket science, done by rocket scientists. No rocket scientist is going to write an optimizer for a Java or C# compiler, it just isn't going to happen, even if it were possible.
Arguments about .net or Java JITters being able to optimize on-the-fly for the specific CPU are true but in practice, this never happens because by definition, Java and C# programmers could care less about speed. And even if they do, the JITter simply doesn't have time to optimize thoroughly.
Assembly language is absolutely neccessary if you want to reach the top in Go programming. Even more so with Go, than with Chess, because Go needs even more speed.
Of course, your algorithms need to be optimal and exploit the CPU's capabilities to the max.
In assembly, you can do cache prefetches, align code and data and insert NOPs. I don't think you can do that in 64-bit C++. This alone makes inline assembly worthwhile.
Since this blog therefore isn't doing much good to persuade potential customers, I'll be heavier on the Programming side of things, so that at least fellow Go programmers might be able to benefit from it.
Which brings us to the topic: Inline Assembly language in our (C, C++ or Pascal, etc.) code. The knee-jerk response to this question is: "Due to the fact that optimization issues on modern CPU's are so complex, modern compilers generate code that is almost always better optimized than a human can do".
Which is 100% correct, but totally irrelevant to the issue!
Because we are not interested in optimized C++ code, we are interested in optimized "optimal" code! Let me explain. C++ and Pascal have "stuff they can do", like adding variables. This translates perfectly to machine opcodes, so a compiler can optimize it well.
But the processor in your computer is able to do a few things that C++ does not provide an interface to. Not all mnemonics have their equivalent higher-level language representation. What if it is possible to design the speed-sensitive part of a TsumeGo move maker/unmaker in such a way that it takes advantage of such instructions? (Hint: It is possible).
Then you're screwed, with C++ or Pascal or Java or whatever you use. Your compiler simply isn't going to compile it to efficient machine instructions, and it never will.
Compilers emit chunks of pre-defined code, mapping a higher level construct to lower-level instructions and then they optimize that output. But that's all they do. They are not creative with exotic opcodes. Yes they can do AND and OR and EXOR, but there are quite a few more interesting instructions that aren't mapped to C++ operands.
This is why, when you are serious about making a tactics module for Go (I mean serious in a quest for total world domination), you don't have much of a chance when you stick to Java or perhaps even the latest C++ compilers because I want to point out that no mainstream C++ compiler that targets 64-bit platforms is able, any more, to do inline assembly! Both Microsoft and Intel removed this feature. And it's a major hassle to maintain separate MASM assembly.
Free Pascal does allow 64-bit inline assembly. I develop MoyoGo's TsumeGo/Tactics module in 64-bit Pascal with inline assembly language. The most successful TsumeGo program, GoTools, is written in Pascal as well.
When you're a twentysomething, you probably know next to nothing about optimization techniques. Comp. Sci. does not have it in the curriculum. Unlike myself, you haven't had to tweak code running on a 1 MHz 8-bit processor. And large multinationals want to own the runtime environment, and because universities are closely affiliated to the corporate world, they have started to focus on "slow" languages like Java and C# .net.
Yes, I know there are compilers for those languages, but the resulting code is not fast, for various reasons, one of which is the concept of a garbage collector. But a language designed with the utmost contempt for speed, designed to be exclusively used where speed is of no concern, never is going to get highly optimizing compilers. Writing a good optimizer is rocket science, done by rocket scientists. No rocket scientist is going to write an optimizer for a Java or C# compiler, it just isn't going to happen, even if it were possible.
Arguments about .net or Java JITters being able to optimize on-the-fly for the specific CPU are true but in practice, this never happens because by definition, Java and C# programmers could care less about speed. And even if they do, the JITter simply doesn't have time to optimize thoroughly.
Assembly language is absolutely neccessary if you want to reach the top in Go programming. Even more so with Go, than with Chess, because Go needs even more speed.
Of course, your algorithms need to be optimal and exploit the CPU's capabilities to the max.
In assembly, you can do cache prefetches, align code and data and insert NOPs. I don't think you can do that in 64-bit C++. This alone makes inline assembly worthwhile.
Delete code done
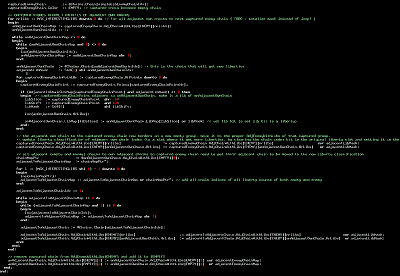 I just finished the "Capture Chain(s)" code. It's less than 100 lines. Horrendously complex lines. In spite of carefully chosen, descriptive identifier names and a flurry of highly elucidating comments, it's not at all obvious what it does and how it does it.
I just finished the "Capture Chain(s)" code. It's less than 100 lines. Horrendously complex lines. In spite of carefully chosen, descriptive identifier names and a flurry of highly elucidating comments, it's not at all obvious what it does and how it does it.When a chain is captured, its adjacent chains get more liberties, but the adjacent chains to those adjacent chains are now adjacent to chains that have a different number of liberties. And I keep a dynamic record of that. So the capture code removes max. four enemy chains, updates the liberty data of all adjacent own chains of those captured chains, and all adjacent chains (empty or enemy) to "own" adjacent chains to captured chains get their adjacent-enemy chain liberty-sorted info rearranged. Because adjacent chains are sorted on how many liberties they have.
This will take more time documenting and debugging than it took to write (3 days). I will never be able to remember all this shit. It looks like a space alien wrote it.
Although tempting, I will not proceed with the "Place Stone / Merge Chains" code, first I'll set up test cases to put what I have now to its paces. I'm eager to see some realistic benchmark differences between a 32-bit and a 64-bit exe.
Friday, May 12, 2006
Tactical Musings
Designing a tactical Go module is also about understanding the underlying hardware.
Most design decisions have an impact on performance, and ultimately it is mostly performance that will provide the advantage over the competition or, more interestingly for Go players, greater playing strength. Because search algorithms and heuristics are plentiful and the very best are freely available. What gives the edge is the speed of the move/unmove engine, the speed & quality of the plausible move generator/orderer and the speed & quality of the evaluation function. Clever pruning schemes are public, but of course the heuristics are a higher form of black magic.
I have made tremendous progress in speed & quality of the plausible move generator with the pattern learning efforts. I've gained experience with the complexity of an efficient state machine required for the board tactics, and now, on a 64-bit architecture, it's "for real".
One of the compromises needed to be made is the tradeoff between maintaining state and the penalties of branch misprediction. I can avoid if's (= branch mispredictions) by maintaining more state, but maintaining state is expensive, in terms of computation as well as in terms of potential cache-trashing.
The obvious solution would be to use bitmaps exclusively, but this only works in theory. In practice, a hybrid solution is optimal because due to Mr. Kernighan & Richie, modern CPU's now don't have the necessary opcodes. They told Intel: "We won't be using them anyway in our compiler" so Intel, happy not to have to debug and regression test all that microcode for all eternity (and free up precious die space), dropped them. By now, they could have been optimized enough to be useful. As I have said before, I need popcount but an instruction to shift to the next set bit and get a running total of the number of shifts required in a register would be even more useful.
Chess programmers belong to different "schools", some delta-update everything they need to maintain, others re-calculate stuff on an as-needed basis, minimizing state size. I am taking the hybrid approach. Things that can be calculated with relative ease, or things that are expected to get an opcode-equivalent in the next decade, are calculated on an as-needed basis. Initial design decicions will be made on the basis of educated guesses. Benchmarking experimental alternatives will be done as soon as building on a sub-optimal solution would constitute a "point-of-no-return".
I don't like to fill the RAM with the state space of the search tree but prefer to stay inside the cache at all times, because the bandwidth gap RAM/cache is steadily widening. I'm betting on ever expanding L1 caches for the Zobrist hash tables. AMD, with its shorter pipelines, holds the performance advantage for TsumeGo stuff, but Intel wins hands down on cache size. I spend enormous time on tweaking the design for the the optium of speed vs. utility. For example, I am maintaining separate lists of chains based on how many liberties they have, because I often need to iterate through chains in atari. But I do not keep their coordinates, because mutating them after a capture is computationally intensive and requires a lot of state-change, potentially trashing the cache. Instead I do a potentially slow bitmap-to-index conversion, until either the CPU supports it in hardware or I find a better algorithm. For that purpose I have just ordered "Hacker's Delight" from Amazon.
I don't think I'll be divulging more about the tactical module. I'll have to read up on Opteron instruction latency and refresh my bitfucking skills, I'll benchmark endlessly, alternated with plenty of "Archimedes" meditation (bathtub brainstorming between my left- & right brain halves :) and slowly something beautiful will emerge. I'm not a singer, painter or a poet - I can't bring beauty to this world. Instead, perhaps one day I can give something I consider beautiful (in its algorithmic implementation) to a select few Go players.
It will be a long and arduous road and success is by no means secure, my weak point is my lack of knowledge of Go heuristics but there have already been published more such -provenly useful- heuristics by strong players/Go programmers than any Go program implements, and the Go knowledge than can be gained from books is of a much higher level than to be found in current Go programs. I will certainly brush up my playing skills, but I prefer Go programming over playing it.
I believe that the Go playing skill required to write a strong Go program is less than the Chess playing skill required to write a strong Chess program, but that is something for another blog entry. There are a few lights on the horizon for Go AI. A disadvantage is the search space and the need to maintain a lot, and, during the search process, wildly changing state, but an advantage is the binary, semi-static nature of the beast and the ternary symmetry of the chains, a key to efficient state maintenance.
My next posting might be a benchmark, comparing the speed of a 64-bit design compiled to a reasonably-optimized 32-bit target (Delphi) to an as-of-yet poorly optimized 64-bit target (Free Pascal).
I am eager to get some comparative results (I have to code a few more weeks). I expect the 64-bit version to be around 3 times faster.
Update: The code is developing into something that translates well to VHDL. It would run much faster on an ASIC with the same frequency as the CPU because a lot of the time-consuming bitboard operations easily can be put into gates. Because the process is massively parallel, it would even be fast on an FPGA.
Most design decisions have an impact on performance, and ultimately it is mostly performance that will provide the advantage over the competition or, more interestingly for Go players, greater playing strength. Because search algorithms and heuristics are plentiful and the very best are freely available. What gives the edge is the speed of the move/unmove engine, the speed & quality of the plausible move generator/orderer and the speed & quality of the evaluation function. Clever pruning schemes are public, but of course the heuristics are a higher form of black magic.
I have made tremendous progress in speed & quality of the plausible move generator with the pattern learning efforts. I've gained experience with the complexity of an efficient state machine required for the board tactics, and now, on a 64-bit architecture, it's "for real".
One of the compromises needed to be made is the tradeoff between maintaining state and the penalties of branch misprediction. I can avoid if's (= branch mispredictions) by maintaining more state, but maintaining state is expensive, in terms of computation as well as in terms of potential cache-trashing.
The obvious solution would be to use bitmaps exclusively, but this only works in theory. In practice, a hybrid solution is optimal because due to Mr. Kernighan & Richie, modern CPU's now don't have the necessary opcodes. They told Intel: "We won't be using them anyway in our compiler" so Intel, happy not to have to debug and regression test all that microcode for all eternity (and free up precious die space), dropped them. By now, they could have been optimized enough to be useful. As I have said before, I need popcount but an instruction to shift to the next set bit and get a running total of the number of shifts required in a register would be even more useful.
Chess programmers belong to different "schools", some delta-update everything they need to maintain, others re-calculate stuff on an as-needed basis, minimizing state size. I am taking the hybrid approach. Things that can be calculated with relative ease, or things that are expected to get an opcode-equivalent in the next decade, are calculated on an as-needed basis. Initial design decicions will be made on the basis of educated guesses. Benchmarking experimental alternatives will be done as soon as building on a sub-optimal solution would constitute a "point-of-no-return".
I don't like to fill the RAM with the state space of the search tree but prefer to stay inside the cache at all times, because the bandwidth gap RAM/cache is steadily widening. I'm betting on ever expanding L1 caches for the Zobrist hash tables. AMD, with its shorter pipelines, holds the performance advantage for TsumeGo stuff, but Intel wins hands down on cache size. I spend enormous time on tweaking the design for the the optium of speed vs. utility. For example, I am maintaining separate lists of chains based on how many liberties they have, because I often need to iterate through chains in atari. But I do not keep their coordinates, because mutating them after a capture is computationally intensive and requires a lot of state-change, potentially trashing the cache. Instead I do a potentially slow bitmap-to-index conversion, until either the CPU supports it in hardware or I find a better algorithm. For that purpose I have just ordered "Hacker's Delight" from Amazon.
I don't think I'll be divulging more about the tactical module. I'll have to read up on Opteron instruction latency and refresh my bitfucking skills, I'll benchmark endlessly, alternated with plenty of "Archimedes" meditation (bathtub brainstorming between my left- & right brain halves :) and slowly something beautiful will emerge. I'm not a singer, painter or a poet - I can't bring beauty to this world. Instead, perhaps one day I can give something I consider beautiful (in its algorithmic implementation) to a select few Go players.
It will be a long and arduous road and success is by no means secure, my weak point is my lack of knowledge of Go heuristics but there have already been published more such -provenly useful- heuristics by strong players/Go programmers than any Go program implements, and the Go knowledge than can be gained from books is of a much higher level than to be found in current Go programs. I will certainly brush up my playing skills, but I prefer Go programming over playing it.
I believe that the Go playing skill required to write a strong Go program is less than the Chess playing skill required to write a strong Chess program, but that is something for another blog entry. There are a few lights on the horizon for Go AI. A disadvantage is the search space and the need to maintain a lot, and, during the search process, wildly changing state, but an advantage is the binary, semi-static nature of the beast and the ternary symmetry of the chains, a key to efficient state maintenance.
My next posting might be a benchmark, comparing the speed of a 64-bit design compiled to a reasonably-optimized 32-bit target (Delphi) to an as-of-yet poorly optimized 64-bit target (Free Pascal).
I am eager to get some comparative results (I have to code a few more weeks). I expect the 64-bit version to be around 3 times faster.
Update: The code is developing into something that translates well to VHDL. It would run much faster on an ASIC with the same frequency as the CPU because a lot of the time-consuming bitboard operations easily can be put into gates. Because the process is massively parallel, it would even be fast on an FPGA.
Tuesday, May 09, 2006
64-bit tactics module in Cross-platform Free Pascal
 I decided to keep MoyoGo written in Pascal by splitting development: Legacy MoyoGo will be in 32-bit Delphi, new code will be in 32/64-bit Free Pascal.
I decided to keep MoyoGo written in Pascal by splitting development: Legacy MoyoGo will be in 32-bit Delphi, new code will be in 32/64-bit Free Pascal.GoTools is written in Pascal as well - I tried to buy a sourcecode licence but Anders Kierulf from SmartGo has bought the sole rights for it for an incredibly huge sum. Thomans Wolf alluded to - sit down - half a million USD. Anders certainly can afford it - being a long-time Microsoftie, he is a multi-millionaire. I was disappointed of course (I offered to make GoTools much better if I got a source licence) but after having talked a lot with Thomas, I now think that it's better to write my own because Thomas never took optimization issues into account. He said "I am a computer scientist, not a software engineer".
This is good news, it means I will have a huge advantage over SmartGo's tactical module for a very long time, because modifying other people's ancient, ported code to have a radically different, 64-bit based design is just about impossible.
I am designing the Tactics module to take advantage of the fact that 64-bit registers manipulate data twice as fast as 32-bit registers. Using a 64-bit compiler will therefore result in a much faster TsumeGo module, also because 64-bit CPU's have double the number of registers and because they are able to do realtime pipeline rescheduling.
Free Pascal supported 64-bit targets before gcc did, and it can target just about anything, from mobile devices to supercomputers.
Saturday, May 06, 2006
The Law of Diminishing Returns
 In order not to fall victim to the Law of Diminishing Returns, I recently started a translation initiative.
In order not to fall victim to the Law of Diminishing Returns, I recently started a translation initiative.One of the problems encountered is that Object Pascal has no out-of-the-box support for Unicode. I used Unicode-enabled 3rd-party widgets here & there but a lot of components don't have any, like the component I made myself, the slider in this picture. It takes some Windows API hacking to make hints support Chinese, but it's worth it. I'm getting a lot of CJK SPAM these days, caused by the fact that Chinese, Japanese and Korean Go forums started linking to me. Almost nobody from those countries buys my software yet, because so far it has not been localized.
It is important I do not lose sight of my goal: Making the world's strongest Go program. This is why I will tone down the "new features" factory and instead focus on bugfixing, small improvements (like adding shortcut buttons and other things my users have suggested).
It has come to my attention that my competitors have re-invigorated their pursuit of building Go-playing software (Mark Boon, for example). They will find a tough competitor in me. My target is to have a search-based Life & Death / Connectivity module by the end of the year, although it will be elligible for continuous improvement, of course.
Thursday, May 04, 2006
Chinese translation
 I won't showcase all translations, but that does not mean I am not very grateful for them.
I won't showcase all translations, but that does not mean I am not very grateful for them.This translation has been provided by Ning (Mace) Lee and it is a milestone! Enchanting, to see Moyo Go in Chinese.
There are a few bugs which make CJK strings display badly in some places, so I have to fix that now.

Monday, May 01, 2006
Retarded Optimization
I'm working on a TsumeGo solver (in the broadest sense of the word, it will also know whether chains can be connected - I'm not sure that classifies as TsumeGo). The (Object Pascal - style) classname is "TTactics". And I wanted to talk about general design issues. Unscrupulous enemies are lurking, so I won't get into details, but I wanted to address something that so far yielded only two Google results: Retarded Optimization.
When constructing a TsumeGo solver, premature optimization is bad. Because you'll be swamped by trivia before the bloody thing works at all.
However: Retarded optimization is just as bad! "Retarded optimization" means it's too late to optimize efficiently.
It takes so much time to write an industrial-strength TsumeGo/Tactics module, that you want to have exactly the right amount of optimization at exactly the right times. You need enough optimization upfront, because after you wrote a few thousand lines of highly complex code, it's too late to change the design paradigm, all you can do is apply speedup tricks that makes the existing design run faster.
The reason it took me so long to get coding on the tactics module (four years) is because I wanted to get the design right. I wanted to design a Ferrari and not a Ford. It's insane to mod a Ford into a Ferrari. It would cost much more time and money to do that than to build a Ferrari from scratch.
Let there be no mistake - my goal is Michael Reiss taking up bonzai cultivation and Fredrik Dahl devoting the rest of his life to Backgammon.
So, while I figured out how to make a good tactics engine, I coded up some simpler stuff, like the program as it is today. I think I know now how to make the very fastest tactics engine. It requires a fast design. After initial implementation, it will be easy to port it to 128 bit SSE3 assembly (a pity there are no 361-bit registers - see my posting "The Case For 64 bits" to see why more bits means more speed in Go programming), but that's all useless if the design wouldn't be the absolute fastest. In that case it's neither premature nor retarded optimization, it would be useless optimization.
Because that's what it comes down to - if the design isn't absolutely optimal, then optimization is pretty useless. It's like tuning a tractor's engine and transmission system to go twice as fast. You still won't outpace a 2CV. So as long as you don't have the "perfect" design, it's pointless to start coding, otherwise you'll have to do it all over again after you figured out that your design sucked and what the best design is. Of course you can build one, throw it away and start all over again (in fact I'm doing that because Moyo Go already contains most of a tactics engine in order to move/unmove, capture chains etc.) but you can't go on building crap forever. Life is short and although coding TsumeGo engines is more satisfying than French kissing Finnish boarding school girls, it still gets boring after a while.
OK. So, in my case, avoiding premature optimization means I don't go bitfucking yet. Everything in its own variable, that kind of thing. BUT, as fellow countryman Terje Mathisen said: "All programming is an exercise in caching". The Norwegian climate is exquisitely suitable to develop software, this is why WinHonte scares me. I do pay great attention to caching issues. Every thing I make is with caching peculiarities in mind. Another design parameter is the ultimately attainable level of optimizability. I even design with hardware-ization ability in mind. Can it be effectively implemented on a FPGA? What about future CPU capabilities? You get the idea. Nothing worse than a design that doesn't survive the future. This is why, four years ago, I started to code Moyo Go with 64-bit integers wherever it would provide a speedup (e.g. Zobrist hashes, bitboards and packed fields). Since yesterday, Free Pascal has a 64-bit compiler :-)
Whenever you're in doubt about the prematureness or tardiness of your optimization: Simplicitity is the hallmark of the professional.
When constructing a TsumeGo solver, premature optimization is bad. Because you'll be swamped by trivia before the bloody thing works at all.
However: Retarded optimization is just as bad! "Retarded optimization" means it's too late to optimize efficiently.
It takes so much time to write an industrial-strength TsumeGo/Tactics module, that you want to have exactly the right amount of optimization at exactly the right times. You need enough optimization upfront, because after you wrote a few thousand lines of highly complex code, it's too late to change the design paradigm, all you can do is apply speedup tricks that makes the existing design run faster.
The reason it took me so long to get coding on the tactics module (four years) is because I wanted to get the design right. I wanted to design a Ferrari and not a Ford. It's insane to mod a Ford into a Ferrari. It would cost much more time and money to do that than to build a Ferrari from scratch.
Let there be no mistake - my goal is Michael Reiss taking up bonzai cultivation and Fredrik Dahl devoting the rest of his life to Backgammon.
So, while I figured out how to make a good tactics engine, I coded up some simpler stuff, like the program as it is today. I think I know now how to make the very fastest tactics engine. It requires a fast design. After initial implementation, it will be easy to port it to 128 bit SSE3 assembly (a pity there are no 361-bit registers - see my posting "The Case For 64 bits" to see why more bits means more speed in Go programming), but that's all useless if the design wouldn't be the absolute fastest. In that case it's neither premature nor retarded optimization, it would be useless optimization.
Because that's what it comes down to - if the design isn't absolutely optimal, then optimization is pretty useless. It's like tuning a tractor's engine and transmission system to go twice as fast. You still won't outpace a 2CV. So as long as you don't have the "perfect" design, it's pointless to start coding, otherwise you'll have to do it all over again after you figured out that your design sucked and what the best design is. Of course you can build one, throw it away and start all over again (in fact I'm doing that because Moyo Go already contains most of a tactics engine in order to move/unmove, capture chains etc.) but you can't go on building crap forever. Life is short and although coding TsumeGo engines is more satisfying than French kissing Finnish boarding school girls, it still gets boring after a while.
OK. So, in my case, avoiding premature optimization means I don't go bitfucking yet. Everything in its own variable, that kind of thing. BUT, as fellow countryman Terje Mathisen said: "All programming is an exercise in caching". The Norwegian climate is exquisitely suitable to develop software, this is why WinHonte scares me. I do pay great attention to caching issues. Every thing I make is with caching peculiarities in mind. Another design parameter is the ultimately attainable level of optimizability. I even design with hardware-ization ability in mind. Can it be effectively implemented on a FPGA? What about future CPU capabilities? You get the idea. Nothing worse than a design that doesn't survive the future. This is why, four years ago, I started to code Moyo Go with 64-bit integers wherever it would provide a speedup (e.g. Zobrist hashes, bitboards and packed fields). Since yesterday, Free Pascal has a 64-bit compiler :-)
Whenever you're in doubt about the prematureness or tardiness of your optimization: Simplicitity is the hallmark of the professional.