The system of automatically updating software is similar, in some respects, to the system of periodic abstention: It's very nice and it usually works, but when something goes wrong, it usually goes quite wrong.
So far, so good.
If I would have to roll out bug-free or feature-complete software, my customers would have to wait until all my hairs were gray. So auto-updates it is. This way, Moyo Go can grow strongest fastest. It is a concept of XP, (eXtreme Programming), that you should release bugfixes and new features often. This speeds up the customer-feedback cycle.
I am not sure whether my customers think I should tone down the updates a little. I don't really know how fast their average internet connection is, for example. But there is always one customer waiting for that one fix or feature. I guess that when they don't want to be bothered too often, they just turn them on when they feel like it. Those who always want the latest version have it on all the time, even if that means they'll sometimes get an update twice a day, or run the risk that they'll have to cope a day with a build in which something is broken that wasn't broken before.
All in all, auto-updating works extremely well, knock on wood. In the ten weeks I've been at it, I've managed to introduce many new features and fixed at least a dozen bugs. It's much better to work with small increments (and get instant feedback), than to hack about for months and release a major new version with zero "real world" usability-testing in the meantime.
For me, the programmer, the update system actually is a complex affair. Moyo Go has no copy-protection, but I have implemented a sort-of anti-piracy measure: Every customer has their own, uniquely encrypted pattern database and the decryption key depends on the checksum of the executable. And the executable itself is packed. I can know which copies update a hundred times per week and are therefore pirated en-masse. I can block automatic updates of that version. I believe that potential pirates who are really serious about some software, will still prefer to pay for software if pirating it means they will not be able to get any updates of the software. And the original owners will not likely allow their software to be pirated, because that means their own updates (which have become identical to the pirated ones) will be jeopardized.
Of course, all this only works when there are updates. But there are.
Some software developers jump through hoops to safeguard their intellectual property, and I'm not one of those. The guys that sold me the installer I use (Ghost Installer, 600 USD) actually phoned me to verify that I wasn't a Chinese hacker or something.. And they do that to all their customers!
Friday, September 30, 2005
Thursday, September 29, 2005
The Tree
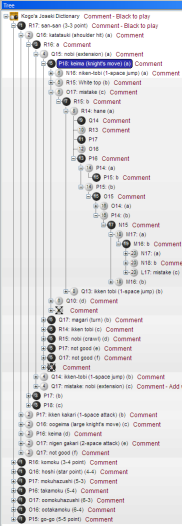 One of the solutions in Moyo Go that I am proud of is the treeview. This treeview is unique: None of the other SGF Editors displays the moves like Moyo Go does. It looks so natural that it isn't even noticeable at first sight, but there is something highly cool going on here. The way the moves are shown is totally user-centric instead of programmer-centric.
One of the solutions in Moyo Go that I am proud of is the treeview. This treeview is unique: None of the other SGF Editors displays the moves like Moyo Go does. It looks so natural that it isn't even noticeable at first sight, but there is something highly cool going on here. The way the moves are shown is totally user-centric instead of programmer-centric.Moves 1 - 5 still look like you would expect in an ordinary tree. But look at moves 9 - 13. They don't sprawl out diagonally, they are below eachother. Because why would you display moves to the user as if the user is interested in the way the programmer has represented the tree structure in memory? The user only wants to have the clearest possible representation of a game and its variations.
Trees can be daunting, so I tried to make things clearer by having the main branch always in white, and the darker the background, the "deeper" in the tree (= the further from the main branch). It's very rare to have the move numbers displayed on the (3D) stones.
There are many more conveniences for SGF authors: Simply click on a node and edit its title. You can zoom the tree. You can change move numbers with a spinner button and immediately see them change on the stones.
No effort has been spared to make this tree a joy to use and it's packed with those little details that make a difference. When you rotate the boards, the move coordinates in the tree update as well.
Like all other windows in Moyo Go, the tree can be "docked" anywhere you want, and it can contain any toolbar, like the navigation toolbar.
Navigation in the tree is done with the cursor keys, but you can also use the mouse wheel to navigate through its branches - as long as the mouse hovers over the board, not the tree itself. (When the mouse is above the tree, the mouse wheel scrolls through it.)
Wednesday, September 28, 2005
Lie on the envelope

This is the bubble envelope that Moyo Go Studio comes in. To keep the cost down to customers, it's not sent by registered mail because only in less than 1% of cases, a letter doesn't arrive in time and in that case I send a new copy but for the contents I write something like "cardboard sample demo". Because my post office asks me 10.75 USD extra to send MoyoGo registered. That's more expensive than sending another copy. That's the disadvantage of living in one of the world's most expensive cities. A beer across the street is 9 USD. One would almost be relieved that summer lasts only two weeks here.
The customs declaration specifies "CD", even when it's a DVD. This is to minimize the risk of theft. It is sent as a "gift" and the value is "none".
Tuesday, September 27, 2005
Standards, which standards?
The computer Go world suffers from a lack of standards, or, to be more exact, enforced standards.
Take player's names, for example. Jan van der Steen has invented a marvellous method of uniquely identifying players. He assigns numbers to them, the socalled PID or "player ID".
I would love to know what his mechanism for assigning them is. I would love to have a list of those PID's. Why? There are so many alternative methods to transliterate Chinese, Japanese and Korean names into English. Hypothetical case: When, in Gobase for example, someone is called "Fu Chien" but in GoGoD "Fu Kien", Moyo Go will only be able to find "Fu Kien" and not "Fu Chien".
In such cases it would be a solution to know the PID, and be able to search on it. Unfortunately, Jan van der Steen sees me as a competitor and he declined to share his PID system with me.
There are more of these problems. Similarly as we are currently unable to uniquely identify players because we somehow don't seem to get along, we also are unable to uniquely identify games. There is the "Dyer Signature" - Moyo Go implements it - but Dyer Signatures are neither universally supported, nor suitable to distinguish between games with minor endgame variations.
Then there is the issue of identifying good and bad moves. Take the marvellous Kogo Joseki Dictionary. Gary Odom has done a terriffic job and permitted me to include it with Moyo Go. Yet I found something to bitch about :)
Namely, the way bad moves are indicated leaves something to be desired: They are indicated simply by a "bad move" comment, instead of the standard SGF property "BM". That's not really Gary's fault, we SGF Editor publishers should make it easier for the user to click a "bad move" button! For computer Go scientists, it is wonderful to have a standardized way of indicating bad moves (especially with omitted comments), so that automatic learning modules know they are bad.
Another point is Unicode. Some SGF contains Unicode without explicitly indicating this. Almost all SGF with Unicode that does indicate this with the proper SGF property does not contain a Byte Order Mark, so that ordinary editors still don't know that the file contains Unicode.
Etcetera, etcetera. Write an SGF parser, and you'll see what I mean. There is so much malformed, downright illegal SGF out there. Not to mention abuse of certain SGF properties, like adding a circle marker after each move (KGS), instead of leaving it to the user, to have the SGF reader show something on the last move or not.
In the meantime, the SGF standard has not really been brought into the 21st century. Where are the properties that cater to multimedia? How do I encode Rich Text, Sound and movies from my webcam? It's left to the individual programmers to invent new properties and encoding standards, if they want to support stuff like that.
I did that, I made up a new SGF property that supports Rich Text, including images and tables.
So far so good. No rocket science. Just take some Rich Text (*.rtf), compress it and then BASE64-encode it because some SGF reader makers complained that their code can't handle bytes that have their MSB set. Fine. So I followed all the rules for well-formed SGF to the letter and put some nice pictures of Go Seigen in my newly defined SGF property. What happened when I tried to load it into [censored] and [censored]? Not just a crash, much worse, a complete lockup of the computer! The programmers never anticipated long SGF properties. (And of course I provided a compatible SGF property as well with the plain-text equivalent).
I informed the perps and hopefully, the newer versions of [censored] and [censored] do support SGF properies of arbitrary length. Since I introduced Rich Text in Moyo Go and sold 100 copies, I have not heard of a single person who has actually used it (the feature is disabled by default, that might have something to do with it). But if any other programmer is interested, the spec of how I encode RTF into BASE64 is open, send me an email and I'll be more than happy to share it with you.
Take player's names, for example. Jan van der Steen has invented a marvellous method of uniquely identifying players. He assigns numbers to them, the socalled PID or "player ID".
I would love to know what his mechanism for assigning them is. I would love to have a list of those PID's. Why? There are so many alternative methods to transliterate Chinese, Japanese and Korean names into English. Hypothetical case: When, in Gobase for example, someone is called "Fu Chien" but in GoGoD "Fu Kien", Moyo Go will only be able to find "Fu Kien" and not "Fu Chien".
In such cases it would be a solution to know the PID, and be able to search on it. Unfortunately, Jan van der Steen sees me as a competitor and he declined to share his PID system with me.
There are more of these problems. Similarly as we are currently unable to uniquely identify players because we somehow don't seem to get along, we also are unable to uniquely identify games. There is the "Dyer Signature" - Moyo Go implements it - but Dyer Signatures are neither universally supported, nor suitable to distinguish between games with minor endgame variations.
Then there is the issue of identifying good and bad moves. Take the marvellous Kogo Joseki Dictionary. Gary Odom has done a terriffic job and permitted me to include it with Moyo Go. Yet I found something to bitch about :)
Namely, the way bad moves are indicated leaves something to be desired: They are indicated simply by a "bad move" comment, instead of the standard SGF property "BM". That's not really Gary's fault, we SGF Editor publishers should make it easier for the user to click a "bad move" button! For computer Go scientists, it is wonderful to have a standardized way of indicating bad moves (especially with omitted comments), so that automatic learning modules know they are bad.
Another point is Unicode. Some SGF contains Unicode without explicitly indicating this. Almost all SGF with Unicode that does indicate this with the proper SGF property does not contain a Byte Order Mark, so that ordinary editors still don't know that the file contains Unicode.
Etcetera, etcetera. Write an SGF parser, and you'll see what I mean. There is so much malformed, downright illegal SGF out there. Not to mention abuse of certain SGF properties, like adding a circle marker after each move (KGS), instead of leaving it to the user, to have the SGF reader show something on the last move or not.
In the meantime, the SGF standard has not really been brought into the 21st century. Where are the properties that cater to multimedia? How do I encode Rich Text, Sound and movies from my webcam? It's left to the individual programmers to invent new properties and encoding standards, if they want to support stuff like that.
I did that, I made up a new SGF property that supports Rich Text, including images and tables.
So far so good. No rocket science. Just take some Rich Text (*.rtf), compress it and then BASE64-encode it because some SGF reader makers complained that their code can't handle bytes that have their MSB set. Fine. So I followed all the rules for well-formed SGF to the letter and put some nice pictures of Go Seigen in my newly defined SGF property. What happened when I tried to load it into [censored] and [censored]? Not just a crash, much worse, a complete lockup of the computer! The programmers never anticipated long SGF properties. (And of course I provided a compatible SGF property as well with the plain-text equivalent).
I informed the perps and hopefully, the newer versions of [censored] and [censored] do support SGF properies of arbitrary length. Since I introduced Rich Text in Moyo Go and sold 100 copies, I have not heard of a single person who has actually used it (the feature is disabled by default, that might have something to do with it). But if any other programmer is interested, the spec of how I encode RTF into BASE64 is open, send me an email and I'll be more than happy to share it with you.
Sunday, September 25, 2005
Secret Opcodes
Every serious hacker sooner or later needs the popcount instruction.
This "population count" instruction counts the set bits in a register, and is so useful that the NSA demands that all computers they purchase implement it in hardware.
Decryption, uncompression (decompression is something divers do :), pattern recognition, Zobrist hashing (generating keys in a certain Hamming distance range) and cellular automata all profit from a "popcount" (better to be called BC) instruction, and the time and effort it saves is very substantial, compared to a kludge in MMX or SSE2, where it's done on 64 or 128 bits in parallel.
But even with hundreds of millions of transistors in current CPU's, there isn't a single mainstream desktop CPU that implements this so-called "canonical NSA instruction".
This reeks of a conspiracy.
The Itaniums and some less prolific CPU's implement it (V9 SPARC and Seymore Cray's Cyber, both at the explicit request of the NSA - as well as Sun's UltraSparc, the PowerPC and Dec's Alpha 21264, heck - even the T800 Transputer had it), but neither the latest Pentiums, nor the latest Opterons support it.
Conspicuously absent, in spite of a billion transistors in real estate.
It wouldn't be the first time that a microprocessor manufacturer (Intel) would implement undocumented opcodes, only to "licence" them to major - sworn to secrecy - software producers.
Those opcodes can have aliases, so that when they leak, they can be traced back to the licencee.
That way, Intel could provide Microsoft with a competitive advantage in producing Codecs and unZIPpers (to give but an example), whilst Microsoft would, for Intel's benefit, delay their 64-bit OS for the Opteron for more than a year, to give Intel time to catch up with AMD. Of course this is all conjecture, but it's inspired by the historical fact that a certain CPU manufacturer has sold the specs to undocumented opcodes before, whilst we all know that Microsoft is getting convicted for illegal monopolistic practices on a regular basis.
In the past there was COCOM, which was a set of export restrictions to prevent the Cold War adversary from getting their hands on powerful CPU's, amongst other things. But nowadays the "enemy" is everywhere, the new enemy uses encryption and the NSA would like to keep the edge.
One of the ways to maintain an edge is to either keep certain capabilities of current CPU's a secret, or to prevent these capabilities from being implemented in affordable mainstream PC's altogether.
If mainstream CPU's would have a popcount instruction, I could make a Go position evaluation function run twice as fast as it does now.
In Go, chains of stones have liberties, and when chains are merged or captured, liberties need to be re-counted.
Merging chains can be done very efficiently using bitboards (as used in chess), and it would be ideal to count liberties using this much missed instruction.
At the moment I need to use a parallellized algorithm that uses MMX or SSE2.
Random Thoughts

When people say: "I built my own computer", they mean they buy a motherboard, drives, CPU, cooling system, RAM, power supply, case and screw and plug it all together.
So I always have to explain that when I say: "I built my first computer myself" I mean that I had to actually solder all components onto the motherboard. (The empty motherboard of my Acorn Atom came with a bag of resistors, IC's, capacitors and connectors).
Still I should not say: "I built my computer myself", for I know a guy that has really done so. He lives in Tbilisi, Republic of Georgia and he showed me his self-made computer. It was unique. He designed the hardware using "Soviet" IC's, and he hand-designed and etched the motherboard in an acid bath. He drilled the holes for the component's wires with a dentist's drill. He wrote the BIOS. He wrote the OS. He wrote the compiler. He wrote the system utilities. Tbilisi had rationed electricity in the early nineties so he powered his computer from old car batteries. Those batteries were refurbished. He had emptied them of battery acid, collected the best plates, washed and cleaned them, hammered them flat again and put them back in the battery casing and filled it up with new acid.If I would really build my own computer today, I would add a very important thing for computer scientists: A crappy carbon resistor or a crappy Germanium diode. In fact I am prepared to pay more for a system that has it.
The thing is, crappy carbon resistors or crappy Germanium diodes noise (verb). The DAI had one. (The DAI hails from the same era as the Acorn Atom, the TRS 80 and the Exidy Sorcerer, around 1980). Such "Johnson" noise is produced by the random movement (Brownian motion largely caused by thermal effects) of electrons in the component (PN junction noise in case of a [Zener]diode or transistor). This is real quantum-randomness. Mathematicians will start to drool at this point. People that use Zobrist hashing will salivate as well.John von Neumann said: "Anyone who considers arithmetic methods of producing random digits is, of course, in a state of sin."
The DAI used quantum noise to generate truly random numbers. You do this by amplifying the noise, Schmitt-triggering it, feeding the pulse train into a shift register and clocking the resulting machine word out. Highly cool. Strange that this is not integrated into modern CPU's. Hundreds of millions of transistors, but nobody thinks of using a handful of them (downgraded to be "noisy") to generate real random numbers fast.
But yet, really good hardware random generators are unwieldy and expensive.
Thermal noise-based random is slow compared to generating "random" numbers with a shift register, but this can be augmented by giving each bit its own random generator, hashing the bits to compensate for the fact that some generators will have an asymmetric duty cycle, and having a constantly filled-up "random cache" with a capacity of a few thousand 64-bit random numbers, to be used as either integers or floats by the CPU. Random numbers would be really random and load into a register in a single clock cycle! This would be near-trivial to do for AMD, Motorola, IBM or Intel. And I want royalties.Why would you need a "perfect" random? I am not a statistician or some kind of dogmatic purist, but I do need one. I make pattern recognizers for "Artificial Intelligence" purposes, excusez le mot ;)
I started with the random generator in Delphi. That one sucked. When you plotted the random on a 1024 x 1024 field, entire patches remained empty. So my pattern recognizer sometimes shot an old lady because it mistook it for a tank (this is a metaphor, it would go too far to explain what my stuff actually does, and why some forms of pattern recognition need really random random).I then decided to generate random numbers myself, ensuring they all were in a certain Hamming distance range from each other. That's allegedly very useful for Zobrist (xor) hashing, to get an even spread (minimize collisions). But then a discussion on the computer Go newsgroup made me have doubts, and I now use a Mersenne Twister. The verdict on that one is still pending.
<tinfoil hat> Note how none of the modern mainstream CPU's/PC's provide functions to decrypt quickly (popcount) or encrypt well (true random), but that older CPU's/PC's did provide this functionality.. </tinfoil hat>The Case For 64 bits
Hardly anyone has a clue as to why 64-bit computing is almost just as cool as the step from 16 bits to 32 bits.
The hard core of the database weenies can tell you that you get a larger address space, and that this is nice.
Nothing much to make the hacker's heart beat faster.
To make matters worse, there have been some benchmarks recently where folks took a 32-bit source, compiled it for 64-bits, ran it, and noticed that it ran slower (one of the reasons is the fact that 64-bit code is bigger and therefore puts more strain on the cache, another reason is that bigger code & data takes longer to fetch from memory).
It is clear that not many really understand what 64-bit code can do for software, apart from being able to address more memory.
So I had a look at my code and I will show you where I use 64-bit variables, and why this makes the code simpler and sometimes extremely much faster (a factor of 4 is not uncommon). Just to be clear: Of course my code only runs that fast when it's compiled by a 64-bit capable compiler, and running on a 64-bit machine running a 64-bit OS.
The point in using 64-bit variables is speed. Unadulterated, blazing speed. What I used to do with hand-optimized MMX assembly, I now do with 64-bit variables. MMX is severely limited (read: slower) compared to full-fledged 64-bit code.
My software for the Asiatic board game of Go could well use an address space larger than 2 GB, in fact I am at that limit right now. During pattern harvesting, I use an array of 134,217,728 64-bit variables. I need more space for other data structures, and some spare RAM to be able to work on my computer while the thing spends weeks number crunching. (I have another PC but it's a bit slower and it doesn't have 2 GB, only 1.5 GB which is just too little for pattern harvesting). So much for the boring part of 64-bits, the increased address space.
64-bit operations afford very major speedups in applications like encryption/decryption, video/audio encoding/decoding, Chess programs, image manipulation and data compression/decompression and I leave it to others to explain the details. I will give concrete examples on how 64 bit variables occur "naturally" in my computer Go program.
1. Patterns
Moyo Go Studio has a pattern matcher. Patterns are, for efficiency's sake, stored as 64-bit hash values. 64 bits is needed to achieve the required reliability. The pattern matcher uses 64-bit random values, it XOR's those values with each other, it looks those values up in an array with 64-bit values, and so on and so forth.
2. Bitboards
Chess programs use them: for every piece-class, they use a 64-bit variable that has a set bit for a piece of that class on the corresponding chessboard coordinate. In Go, bitboards are highly useful as well, but unfortunately they do not fit into a single 64-bit variable. That does not mean we should revert to a bunch of 32-bit variables - of course we want the largest width available that the compiler supports. Our code will be smaller, simpler and faster. Moyo Go's bitboards are records consisting of seven 64-bit variables, and operations on those bitboards go about three times faster when they are done in native 64-bit as opposed to 32-bit (or 32-bit opcodes simulating 64-bit variables by combining two 32-bit values).
3. Operations on bitfields
Moyo Go uses all kinds of databases (games, patterns, players) and the amount of data is so massive that every trick in the book is used to compress the data. Otherwise the software would not fit on a CD. Of course you can use bitfields in 32-bit variables, but as soon as a unit of data exceeds 32 bits and you need to sort them, you need to do two separate swaps of two 32-bit values instead of a single swap of a 64-bit value. The same goes for manipulations on bitfields. Things go faster when everything is in a single CPU register, and you save registers as well. 64-bit CPU's have not only the ability to operate on two 32-bit values in a single instruction, they also have more registers, something the optimizer can take advantage of. I use 64-bit variables to hold data collections. a 64-bit variable can hold the (max.) four coordinates of any adjacent chains and their color. So instead of using four variables, I use a single 64-bit variable.
4. Copying state
Search algorithms can be sped up by clever "state"-bookkeeping and that involves the copying back of previous states. Memory is most efficiently copied 64 bits or more at a time. Often, the OS should be able to do this most efficiently but whenever you use a loop to copy memory, 64-bit variables are faster than 32-bits.
There are many more places where 64-bit variables are the most natural and fastest solution, and I am simply flabberghasted that so few programmers realize it. Apart perhaps from simple databases, I can't think of any kind of software that would not benefit of their use. (In fact, people have told me that even "trivial" databases would benefit).
The hard core of the database weenies can tell you that you get a larger address space, and that this is nice.
Nothing much to make the hacker's heart beat faster.
To make matters worse, there have been some benchmarks recently where folks took a 32-bit source, compiled it for 64-bits, ran it, and noticed that it ran slower (one of the reasons is the fact that 64-bit code is bigger and therefore puts more strain on the cache, another reason is that bigger code & data takes longer to fetch from memory).
It is clear that not many really understand what 64-bit code can do for software, apart from being able to address more memory.
So I had a look at my code and I will show you where I use 64-bit variables, and why this makes the code simpler and sometimes extremely much faster (a factor of 4 is not uncommon). Just to be clear: Of course my code only runs that fast when it's compiled by a 64-bit capable compiler, and running on a 64-bit machine running a 64-bit OS.
The point in using 64-bit variables is speed. Unadulterated, blazing speed. What I used to do with hand-optimized MMX assembly, I now do with 64-bit variables. MMX is severely limited (read: slower) compared to full-fledged 64-bit code.
My software for the Asiatic board game of Go could well use an address space larger than 2 GB, in fact I am at that limit right now. During pattern harvesting, I use an array of 134,217,728 64-bit variables. I need more space for other data structures, and some spare RAM to be able to work on my computer while the thing spends weeks number crunching. (I have another PC but it's a bit slower and it doesn't have 2 GB, only 1.5 GB which is just too little for pattern harvesting). So much for the boring part of 64-bits, the increased address space.
64-bit operations afford very major speedups in applications like encryption/decryption, video/audio encoding/decoding, Chess programs, image manipulation and data compression/decompression and I leave it to others to explain the details. I will give concrete examples on how 64 bit variables occur "naturally" in my computer Go program.
1. Patterns
Moyo Go Studio has a pattern matcher. Patterns are, for efficiency's sake, stored as 64-bit hash values. 64 bits is needed to achieve the required reliability. The pattern matcher uses 64-bit random values, it XOR's those values with each other, it looks those values up in an array with 64-bit values, and so on and so forth.
2. Bitboards
Chess programs use them: for every piece-class, they use a 64-bit variable that has a set bit for a piece of that class on the corresponding chessboard coordinate. In Go, bitboards are highly useful as well, but unfortunately they do not fit into a single 64-bit variable. That does not mean we should revert to a bunch of 32-bit variables - of course we want the largest width available that the compiler supports. Our code will be smaller, simpler and faster. Moyo Go's bitboards are records consisting of seven 64-bit variables, and operations on those bitboards go about three times faster when they are done in native 64-bit as opposed to 32-bit (or 32-bit opcodes simulating 64-bit variables by combining two 32-bit values).
3. Operations on bitfields
Moyo Go uses all kinds of databases (games, patterns, players) and the amount of data is so massive that every trick in the book is used to compress the data. Otherwise the software would not fit on a CD. Of course you can use bitfields in 32-bit variables, but as soon as a unit of data exceeds 32 bits and you need to sort them, you need to do two separate swaps of two 32-bit values instead of a single swap of a 64-bit value. The same goes for manipulations on bitfields. Things go faster when everything is in a single CPU register, and you save registers as well. 64-bit CPU's have not only the ability to operate on two 32-bit values in a single instruction, they also have more registers, something the optimizer can take advantage of. I use 64-bit variables to hold data collections. a 64-bit variable can hold the (max.) four coordinates of any adjacent chains and their color. So instead of using four variables, I use a single 64-bit variable.
4. Copying state
Search algorithms can be sped up by clever "state"-bookkeeping and that involves the copying back of previous states. Memory is most efficiently copied 64 bits or more at a time. Often, the OS should be able to do this most efficiently but whenever you use a loop to copy memory, 64-bit variables are faster than 32-bits.
There are many more places where 64-bit variables are the most natural and fastest solution, and I am simply flabberghasted that so few programmers realize it. Apart perhaps from simple databases, I can't think of any kind of software that would not benefit of their use. (In fact, people have told me that even "trivial" databases would benefit).
Big Iron vs. the µISV
We small Independent Software Developers (micro-ISV's) should not be afraid of large software companies. Look at Microsoft, for example:
 A while ago, three of their boffins spent quite some time trying to copy my research, but they admit in their cover letter that they fell short. I am not a Ph.D. so I didn't understand their paper much. In fact I have been a beach bum while they were doing their homework:
A while ago, three of their boffins spent quite some time trying to copy my research, but they admit in their cover letter that they fell short. I am not a Ph.D. so I didn't understand their paper much. In fact I have been a beach bum while they were doing their homework:
 Now don't I look like a "terrorist".. The areas where I dwelled the longest (Taba, Sharm el Sheikh and Ras Satan) have, in the meantime, all been bombed by "Al Qaida". But to return to the topic: Large software companies by definition are unable to produce good software. It's pretty sad that even after years of development and aquisition by Google, Blogger's "Upload Image" still doesn't work. And don't get me started on MS products. Simple things like typing a word in a certain font does not work. Copying files does not work. Cut & paste doesn't work (Why would I want to copy a trailing space when I double-click a word?) No Microsofties, I am neither impressed nor afraid.
Now don't I look like a "terrorist".. The areas where I dwelled the longest (Taba, Sharm el Sheikh and Ras Satan) have, in the meantime, all been bombed by "Al Qaida". But to return to the topic: Large software companies by definition are unable to produce good software. It's pretty sad that even after years of development and aquisition by Google, Blogger's "Upload Image" still doesn't work. And don't get me started on MS products. Simple things like typing a word in a certain font does not work. Copying files does not work. Cut & paste doesn't work (Why would I want to copy a trailing space when I double-click a word?) No Microsofties, I am neither impressed nor afraid.
A while ago, three of their boffins spent quite some time trying to copy my research, but they admit in their cover letter that they fell short. I am not a Ph.D. so I didn't understand their paper much. In fact I have been a beach bum while they were doing their homework:Now don't I look like a "terrorist".. The areas where I dwelled the longest (Taba, Sharm el Sheikh and Ras Satan) have, in the meantime, all been bombed by "Al Qaida". But to return to the topic: Large software companies by definition are unable to produce good software. It's pretty sad that even after years of development and aquisition by Google, Blogger's "Upload Image" still doesn't work. And don't get me started on MS products. Simple things like typing a word in a certain font does not work. Copying files does not work. Cut & paste doesn't work (Why would I want to copy a trailing space when I double-click a word?) No Microsofties, I am neither impressed nor afraid.
"I don't play Go myself"
 ..Yet, I am utterly fascinated by the game and if it weren't for the fact that my talent lies more in programming Go rather than playing it, I would spend a lot of time playing online. Above are some notes I made last year, when trying to design an algorithm to recognize Seki.
..Yet, I am utterly fascinated by the game and if it weren't for the fact that my talent lies more in programming Go rather than playing it, I would spend a lot of time playing online. Above are some notes I made last year, when trying to design an algorithm to recognize Seki.Of course I'm not totally ignorant about the game - I have played it at least a dozen times and even managed to win few times from a 12 Kyu. I intend to become a regular player in the near future because it's important to use one's software oneself. Besides, Playing Go is good for the soul :)
Skinned

This surrealistic goban is a MoyoGo board skin. You can make your own skins - simply use Google Image Search for a nice picture and let MoyoGo do the rest.
Natto
 After trying several brands, I found the perfect natto (bacterially fermented soya beans). To stay on the topic of "multi- threading": It is not too slimy that it pulls permanent threads, made with 100% whole beans and with mustard in addition to soya sauce.
After trying several brands, I found the perfect natto (bacterially fermented soya beans). To stay on the topic of "multi- threading": It is not too slimy that it pulls permanent threads, made with 100% whole beans and with mustard in addition to soya sauce.I like natto, but it also helps against osteoporosis. Due to neuroborreliosis, I have been taking megadosed antibiotics for the past five years. This kills the gut flora (which produces vitamin K, which is needed for healthy bones). Natto contains a lot of vitamin K.
The Birth of a New Machine
 Finally!
Finally!It has been quite a challenge to build a new PC. The problem was not putting all the parts together, but getting them to work properly.

The machine in this picture is a dual Opteron dual-core 275, one of the fastest personal workstations on the planet. Sporting dual 20.3" LCD's, 4 GB RAM, several 15,000 rpm SCSI disks, 43,000 MIPS, 18 GFLOPS and 10 GB/s RAM bandwidth, its price tag is a whopping 11,000 USD - an investment into Moyo Go Studio's future. The next major development (apart from bugfixing and implementing features suggested by users) will be a massively multithreaded, 64/128-bit TsumeGo module, and this machine is where it will all come together. Now the only thing I still need is a gun, so that nobody will come and take it away from me :)
Why such an enormous expense? Ordinary desktop PC's of the future will have dozens of "cores", which are separate processors, the powerhouses of the computer. And they will all be 64-bit as opposed to 32-bit. Go software that does not anticipate this, will be doomed to play a minor role. Compared to what the average Go player will have on their desktop in a mere five years, my Colossus is not even special. Add to this the generous oil-wealth inspired Norwegian "HjemmePC Ordningen" - my employer lends me half and the government pays the other half - and I couldn't resist. UPDATE: I recently resigned my job so I had to pay almost the full price..
A major problem in creating a strong Go program is the speed of current computers, so taking full advantage of the (near) future's multi-core 64 bit desktop PC's is essential to staying ahead and coming out on top, eventually.